

Если Googlebot
не может получить доступ к файлу robots.txt из-за ошибки 5xx, то он не будет
сканировать сайт. Об этом заявил один из сотрудников команды поиска на Google
Webmaster Conference, которая прошла в начале
этой недели в штаб-квартире компании GooglePlex.
Согласно Google, при сканировании robots.txt ошибка 5xx возвращается в 5% случаев, в 69% — краулер получает код ответа сервера 200 или 404, а в 26% — файл robots.txt совсем недоступен.
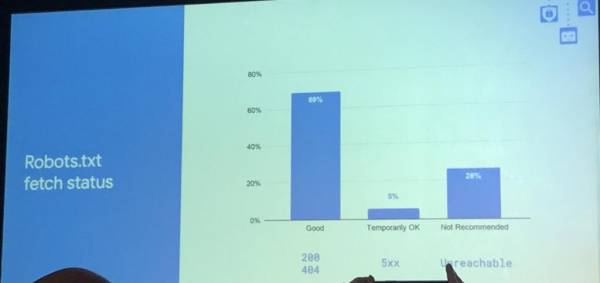
После выхода материала Search Engine Land, в котором изначально говорилось о том, что Google не будет сканировать сайт, если файл robots.txt существует, но недоступен (т.е. в 26% случаев), в Twitter начали активно обсуждать этот вопрос. Совместными усилиями западным специалистам удалось выяснить, что на самом деле речь шла о 5% случаев, когда сервер возвращает ошибку 5xx.
Соответствующая поправка была внесена
и в статью Search Engine Land.
Если файла robots.txt нет, то Google будет считать, что
никаких запретов на сканирование нет:
Основатель Yoast SEO Джуст
де Вальк также поинтересовался, какая часть из 26% случаев, когда
robots.txt недоступен, относится к WordPress, и стоит ли обратить внимание на
то, как WP генерирует эти файлы.
Сотрудник Google Гэри
Илш ответил, что с WP обычно нет проблем, но он ещё дополнительно проверит.
Прочитать подробнее о заявлениях Google по поводу сканирования и ознакомиться с другими интересными тезисами из докладов сотрудников поиска на Webmaster Conference можно в нашем материале по ссылке.
Источник: searchengines.ru


