
Прогноз коэффициента конверсии можно рассчитать даже в том случае, если у вас не хватает статистики. В предыдущей статье мы на наглядных примерах показали, как получить прогнозные значения для ключевых слов, которые набрали совсем мало кликов и конверсий. Сегодня мы расскажем, как с помощью тех же формул получить прогноз конверсии в Power BI.
Методика и формула расчета
Прогнозные значения CR (коэффициента конверсии) мы получаем с помощью многоуровневого пулинга. Благодаря этому методу можно не переживать из-за недостатка статистики: если данных по какой-то сущности (ключевому слову, объявлению, кампании, аккаунту) не хватает, то в расчет берутся показатели для сущности уровнем выше. Например, когда недостаточно статистики по ключевым словам при расчете используются данные соответствующей группы объявлений.
Напомним формулу расчета прогнозируемого CR для сущностей, по которым нет достаточного объема данных. В нее включаются клики и конверсии для текущей сущности, CR для сущности уровнем выше и степень пулинга, которая в нашем случае приравнивается к единице.
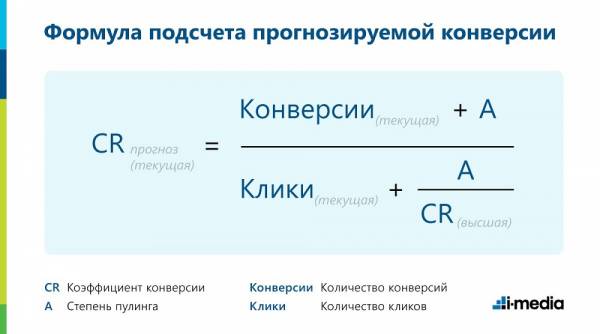
Еноты снова в деле
Как и в первой статье, мы будем рассчитывать прогноз CR на примере интернет-магазина мягких игрушек. В нашем воображаемом магазине продаются только плюшевые слоны и еноты, поэтому семантическое ядро включает 16 ключевых фраз, распределенных по кампаниям «Слоны» и «Еноты». Чтобы рассчитать прогноз для каждого ключевого слова, нам придется сначала определить CR для более высоких сущностей: аккаунта, кампаний и групп признаков.
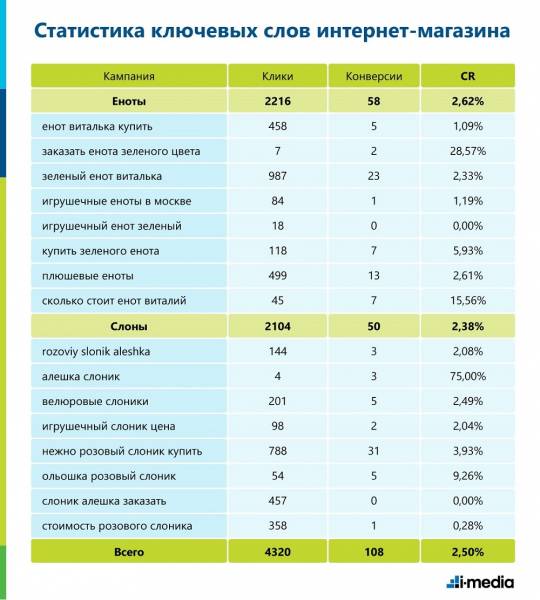
Основные функции Power Query
Предполагается, что читатель хотя бы поверхностно знаком с интерфейсом Power BI, языком M для Power Query и языком Dax. Для тех, кто пока не может похвастаться такими знаниями, мы подготовили описание функций Power Query, необходимых для обработки данных и расчета прогноза. Остальные могут смело пропустить эту часть.
Прежде всего отметим, что в Power Query нельзя редактировать отдельные ячейки по координатам (X,Y), как в Excel. Преобразование происходит на уровне столбцов. А вот опции, которые нам пригодятся:
1. Use first row as headers. Первая строка загруженной таблицы будет использоваться в качестве источника заголовков.
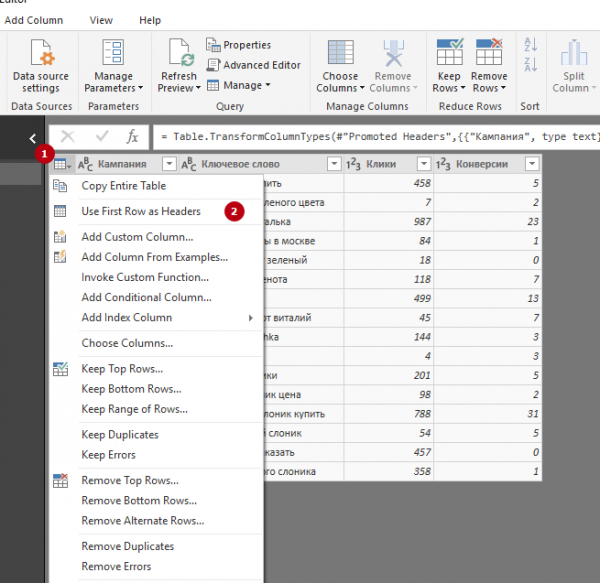
2. Выбор типа данных в столбцах.
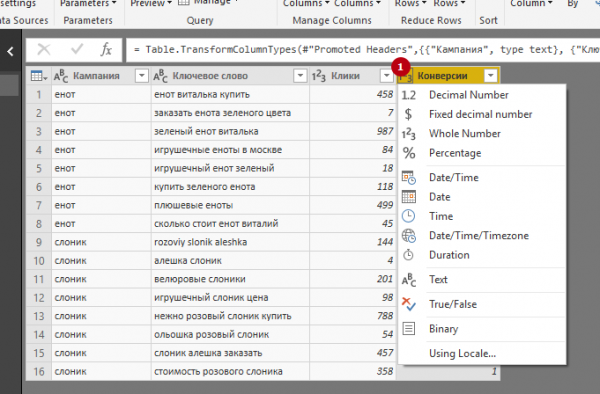
Вот основные типы данных (про остальные можно узнать в официальной справке Power BI):
- Decimal Number (числовые данные с «плавающей» запятой).
- Fixed Decimal Number (числовые данные с фиксированной запятой). Обычно этот формат используется в столбцах, которые содержат значения в какой-либо валюте (CPC, CPA, расход, доход и т.д.).
- Whole Number (целое число). Этот тип данных предназначен для столбцов с показателями, которые могут выражаться только целыми числами (клики, конверсии, показы).
- Text (текстовые данные). Формат подходит для столбцов с названиями кампаний, ключевыми словами, различными статусами, признаками, значениями геотаргетинга и т. п.
Тип данных можно задавать и для нескольких столбцов сразу. При нажатой клавише CTRL выделите нужные столбцы, затем нажмите правую кнопку мыши и выберите в меню Change Type.
Иногда при смене типа данных в столбце появляются ошибки. Чаще всего это происходит при работе с показателями из Яндекс.Метрики и Яндекс.Директа, связанными с денежными единицами (расходом, доходом и другими). В этом случае нужно открыть список с типами данных и выбрать пункт Using Locale. Во всплывающем окне задайте тип данных, в нижнем списке English (United States).
3. Переименование столбцов. Опция доступна после двойного клика по заголовку столбца. Задавайте короткие и простые заголовки, которые ясно описывают данные в столбце.
4. Округление числовых данных с «плавающей» запятой до нужного разряда. Наведите курсор на столбец, нажмите правую кнопку мыши и выберите Transform — Round — Round. После этого задайте нужное число знаков после запятой.
5. Добавление нового столбца по заданному правилу. Откройте вкладку Add Column и нажмите на кнопку Custom Column.
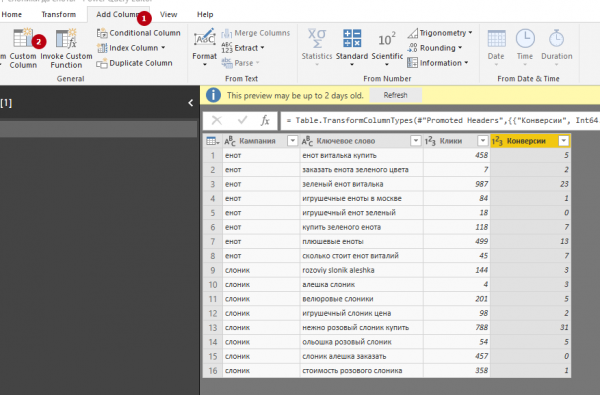
В загрузившемся окне задайте название столбца и правило, в соответствии с которым будут формироваться значения в новом столбце. В поле Available Columns отображается список уже имеющихся столбцов. Двойной клик по столбцу добавляет его правило.
В нашем примере новый столбец «Кампания-Ключ» будет содержать данные из столбцов «Кампания» и «Ключевое слово», разделенные дефисом.
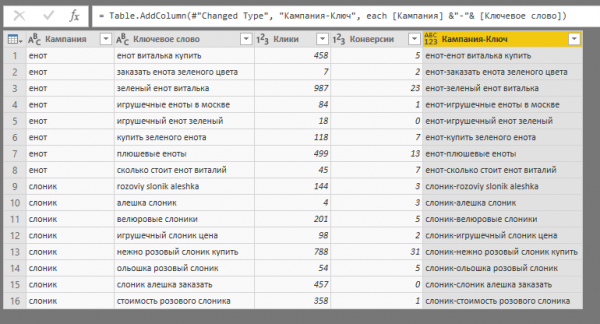
6. Разбивка данных в столбце по делителю. Опция используется повсеместно, например, при отделении минус-слов от ключевой фразы. Давайте для примера разделим столбец «Кампания-Ключ», который мы только что создали, на два новых. Наводим курсор на столбец, нажимаем правую кнопку мыши и выбираем Split Column — By Delimiter.
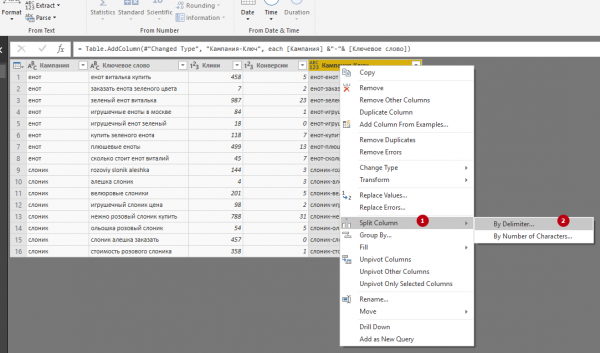
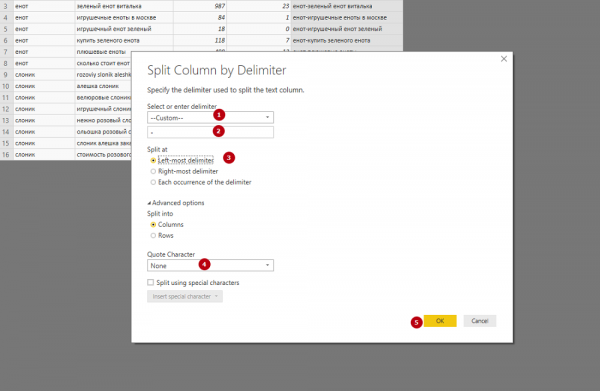
В загрузившемся окне выбираем Custom и прописываем делитель (в нашем случае — дефис). Затем выбираем Left-most delimiter («Делить по самому левому делителю», то есть по первому дефису, который обнаружится в столбце при чтении слева направо). Раскрываем список Advanced Options и задаем None в поле Quote Character. В противном случае кавычки (например, вокруг ключевых слов) просто исчезнут после разделения. Обратите внимание, что сам делитель при разбивке на столбцы пропадает.
7. Удаление столбца. Наводим курсор на столбец, нажимаем правую кнопку мыши и выбираем Remove.
8. Дублирование столбца со всеми его значениями. Наводим курсор на столбец, нажимаем правую кнопку мыши и выбираем Duplicate.
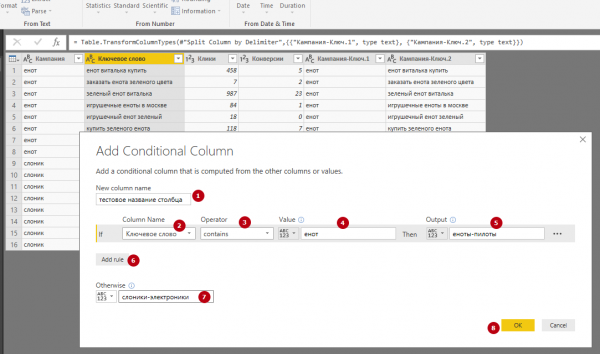
9. Добавление условного столбца. Опция позволяет добавлять столбцы, значения в которых определяются на основе значений из других столбцов. Например, можно добавить столбец со значениями «еноты-пилоты» (для ключей, содержащих слово «енот») и «слоники-электроники» (для всех остальных). Открываем вкладку Add Column и нажимаем кнопку Conditional Column. В загрузившемся окне:
- задаем название нового столбца;
- в поле Column Name выбираем столбец, данные которого станут основой для правил;
- в поле Operator выбираем Contains («Содержит»);
- в поле Value задаем правило для отбора («енот»);
- в поле Output задаем значение, которое будет отображаться в новом столбце при соблюдении правила («еноты-пилоты»);
- в поле Otherwise задаем значение, которое будет отображаться в новом столбце при несоблюдении правила («слоники-электроники»).
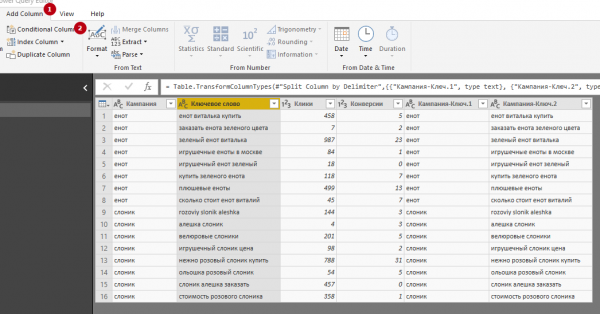
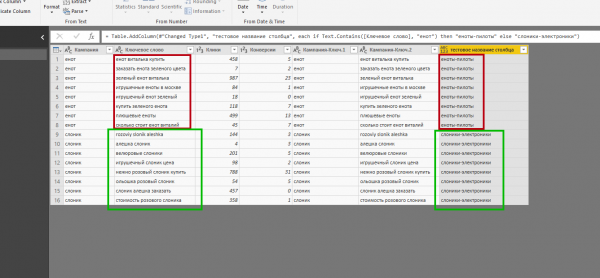
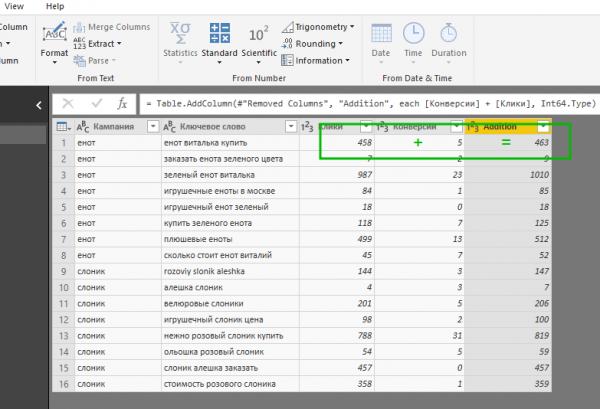
10. Добавление столбца с одновременным выполнением арифметических операций со значениями из других столбцов. К примеру, мы можем создать столбец, в котором будут суммироваться значения столбцов «Клики» и «Конверсии» (на практике такой столбец, конечно, никому не понадобится, но нас интересует, как работает функция). При нажатой клавише CTRL выделите нужные столбцы. Затем откройте вкладку Add Column, нажмите кнопку Standard и выберите нужную операцию. Обратите внимание, что при делении и вычитании важен порядок выделения столбцов. Тип данных во всех столбцах должен быть числовым.
Создание основной таблицы данных в Power Query
Для начала нам нужно импортировать статистику по запросам из Excel:
1. Открываем Power BI, создаем новый файл в формате pbix и нажимаем в загрузившемся на кнопку Get Data.
2. Затем выбираем нужный источник данных (Excel) и загружаем файл в формате .xlsx или .csv (в Power BI можно импортировать данные из множества разных источников, но начинают все обычно с этого).
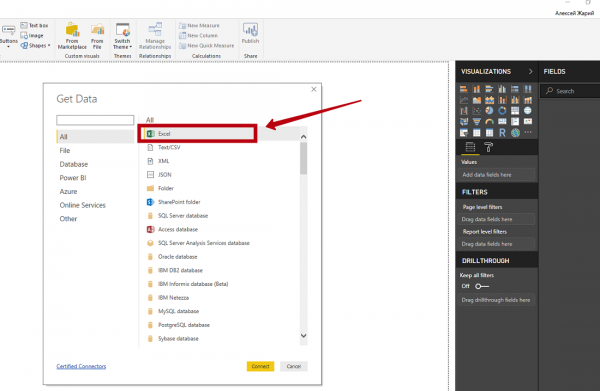
3. В окне Navigator отмечаем лист, на котором находятся данные, и нажимаем кнопку Edit.
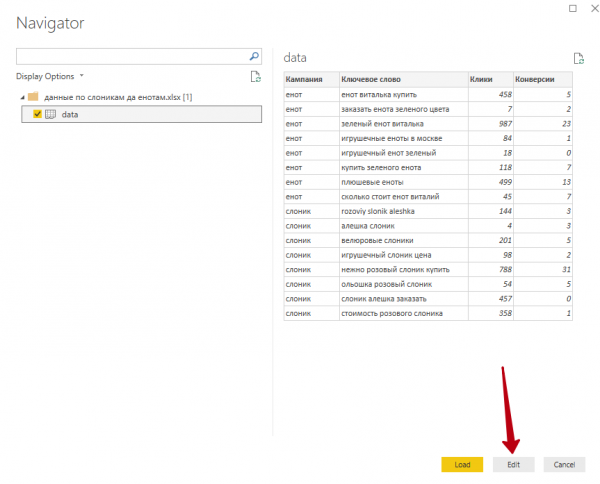
4. Наша таблица откроется в Power Query — инструменте для загрузки и преобразования данных. Теперь нужно задать правильный тип данных для каждого из столбцов. После этого нажимаем кнопку Close and Apply и переходим из Power Query в Power Pivot.
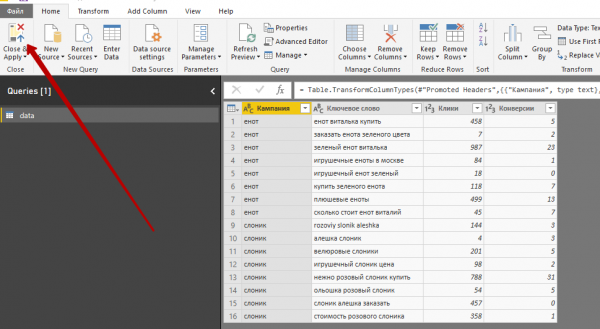
Расчет фактического CR в Power Pivot
Начнем с небольших пояснений для тех, кто не знаком с интерфейсом Power BI. На скриншоте ниже отмечены:
В левой части интефейса находятся кнопки Report, Data и Model. Report — это и есть наш отчет, в котором мы выводим и визуализируем данные. Data — данные, загруженные из Power Query. Model — вкладка, на которой можно связывать таблицы друг с другом (в нашем случае она не понадобится).
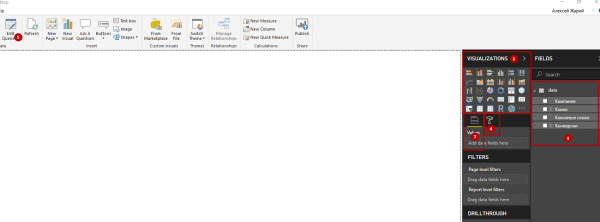
Теперь подготовим таблицу для дальнейшей работы:
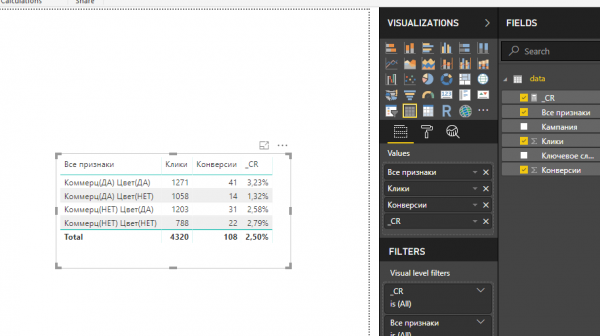
1. Выбираем визуализацию Table и перетаскиваем нужные столбцы в Values (либо отмечаем соответствующие чек-боксы).
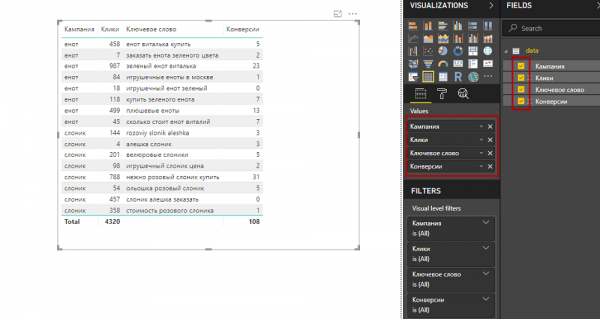
2. Расставляем столбцы в таблице в правильном порядке, перемещая их названия внутри Values.
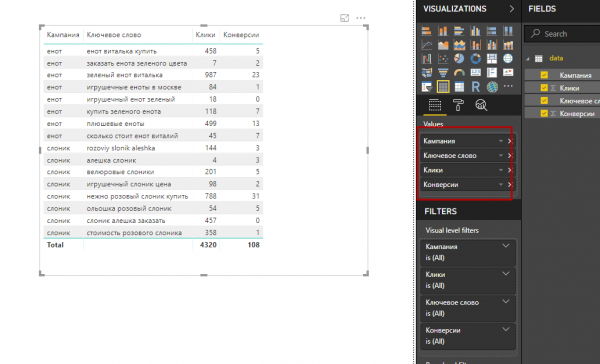
3. Чтобы добавить в таблицу фактический CR, открываем вкладку Modeling и нажимаем кнопку New Measure.
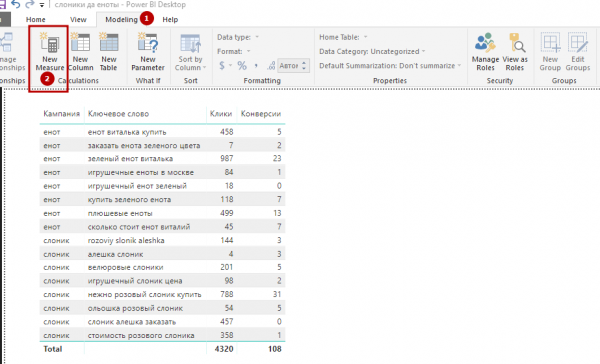
4. Загрузится строка для ввода формулы. Это поле лучше развернуть, поскольку чаще всего формула состоит из нескольких строчек.
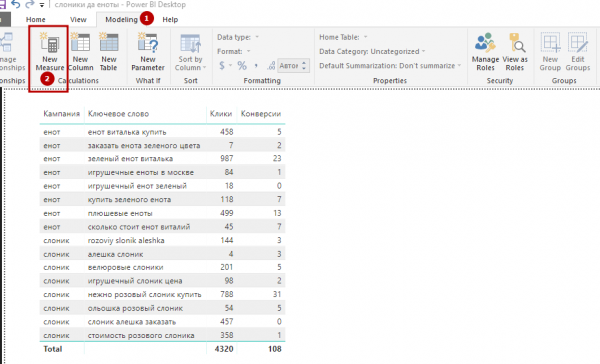
5. Задаем формулу для расчета CR:

6. Результаты расчетов появятся в списке загруженных данных (на первом месте, поскольку название меры мы прописали с нижнего подчеркивания). Чтобы добавить столбец с фактическим CR в таблицу, перетащим его в Values.
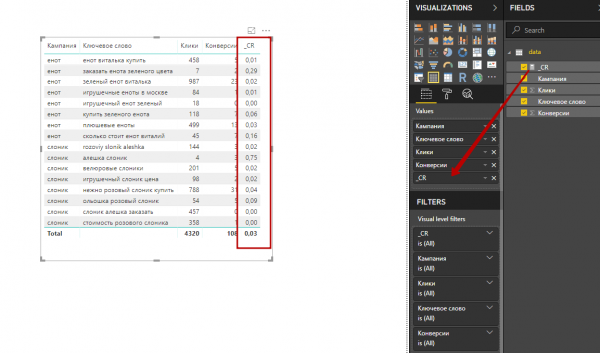
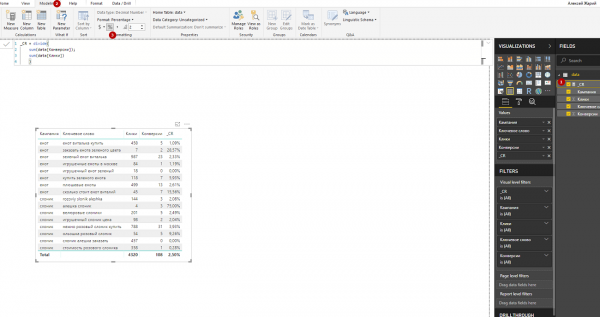
7. Чтобы фактический CR отображался в процентном формате, выделим меру (вокруг нее должна появиться желтая рамка), откроем вкладку Modeling и нажмем кнопку %.
Загрузка данных о признаках ключевых слов в Power Query
Чтобы получить прогноз CR для отдельных ключевых слов, нам нужно рассчитать этот показатель для групп, включающих фразы с определенным набором признаков. Напомню, что мы разделили все ключевые слова по двум признакам: указанию на цвет («Цвет») и интересу к покупке («Коммерц»). Теперь нам нужно:
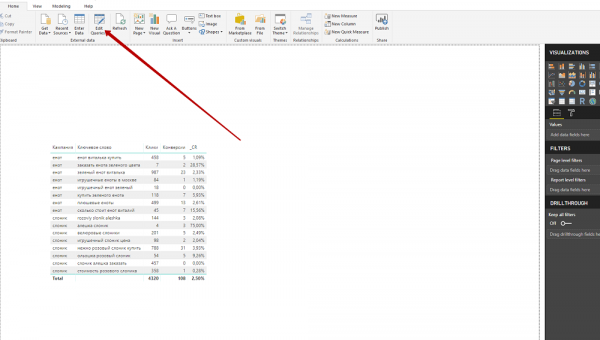
1. Нажать на кнопку Edit Queries, чтобы вернуться в Power Query, и загрузить файл с разбивкой ключевых фраз по признакам.
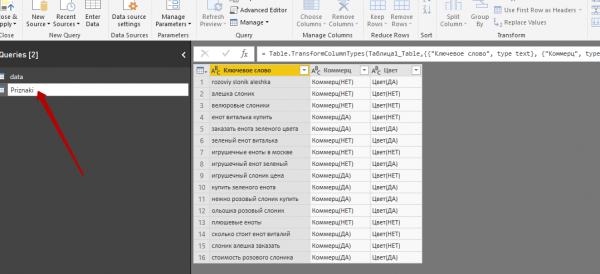
2. В меню Queries отобразятся две таблицы: одна с данными по кликам и конверсиям для каждой из фраз («data») и вторая, содержащая признаки ключевых слов («Priznaki»).
3. Чтобы добавить признаки в «data», выберем эту таблицу в меню Queries, откроем вкладку Home и нажмем кнопку Merge queries.
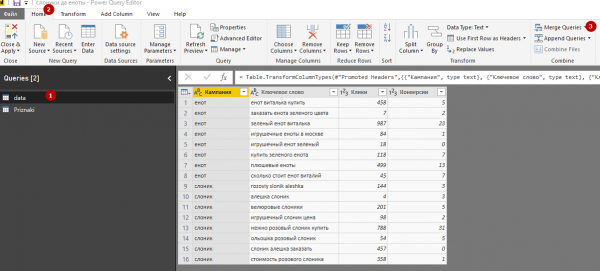
4. В окне Merge выбираем связуемые столбцы в обеих таблицах («Ключевое слово») и нажимаем кнопку ОК.
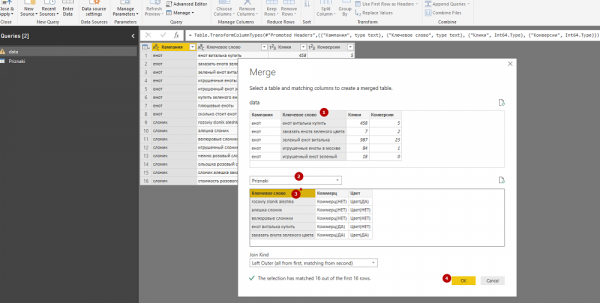
5. В таблице с данными о кликах и конверсиях появился новый столбец «Priznaki». Нажимаем кнопку рядом с его названием и выбираем столбцы, которые нужно добавить из таблицы «Priznaki» в таблицу «data».
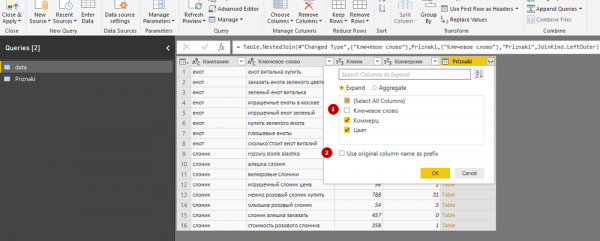
6. В «data» появились столбцы «Цвет» и «Коммерц», которые теперь нужно объединить в столбец «Все признаки». Открываем вкладку Add Column и нажимаем кнопку Custom Column. Затем задаем название нового столбца и правило, по которому в нем будут формироваться значения. Чтобы задать правило, выбираем в поле Available columns столбец «Коммерц», прописываем &” “&, выбираем столбец «Цвет» и нажимаем ОК.
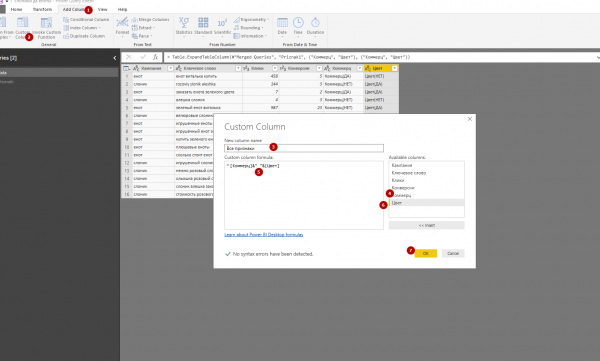
7. В таблице появляется столбец «Все признаки». Столбцы «Цвет» и «Коммерц» можно удалить.
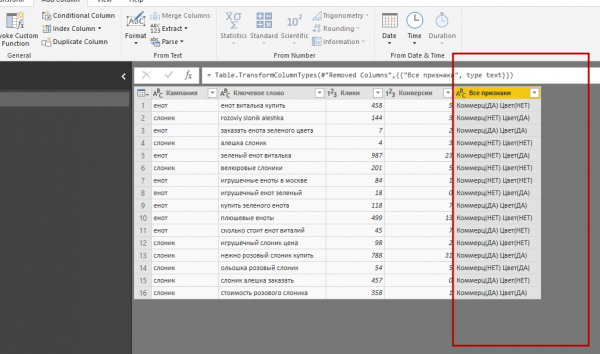
8. Теперь нужно сделать так, чтобы запрос «Priznaki» не подгружался, ведь данные по признакам мы уже подтянули и никакой необходимости во втором запросе нет (однако удалять его нельзя, поскольку данные из «Priznaki» используются в главной таблице «data»). Чтобы отключить загрузку, в списке Queries выберите «Priznaki», нажмите правую кнопку мыши и снимите галочку с Enable Load.
9. Наконец-то все готово! Нажимаем кнопку Close and Apply, выходим из Power Query и возвращаемся в Power Pivot.
Расчет прогнозных значений CR в Power Pivot
Итак, мы вышли на финишную прямую:
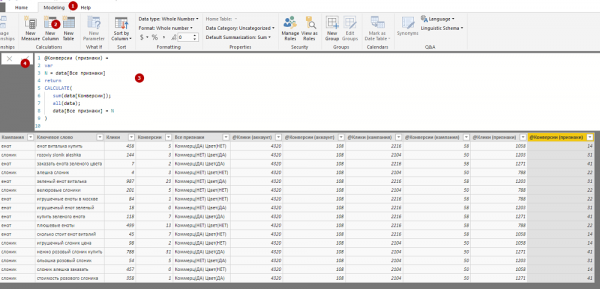
1. В списке загруженных данных теперь отображается столбец «Все признаки». Добавим его в нашу таблицу, а заодно удалим столбцы «Ключевое слово» и «Кампания». Таблица станет меньше, статистика кликов и конверсиям агрегируется для каждой группы признаков.
2. Откроем меню Data и добавим в таблицу столбцы «@Клики (аккаунт)», «@Конверсии (аккаунт)», «@Клики (кампания)», «@Конверсии (кампания)», «@Клики (признаки)» и «@Конверсии (признаки)». Чтобы добавить новый столбец, открываем вкладку Modeling, нажимаем кнопку New Column и вводим нужную формулу.

3. В таблице отобразится суммарное количество кликов и конверсий для каждой из сущностей (аккаунт, кампания, признаки), к которой принадлежит конкретное ключевое слово.
4. Чтобы рассчитать прогноз CR по схеме, которая описана в прошлой статье, добавляем в таблицу столбцы «@Прогн. CR (аккаунт → кампания)», «@Прогн. CR (кампания → признаки)», «@Прогн. CR (признаки → ключевое слово)» и задаем соответствующие формулы.

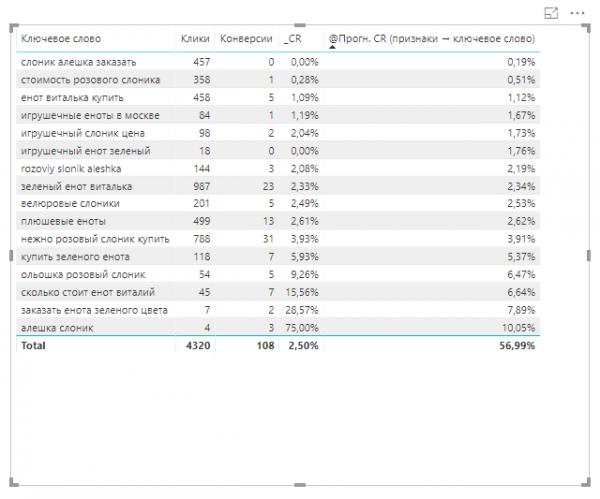
5. Последняя формула позволяет нам получить заветные показатели — прогнозы коэффициента конверсии для каждого ключевого слова. Чтобы корректно оформить полученные результаты, вернемся в Reports и выберем среди вариантов визуализации таблицу.
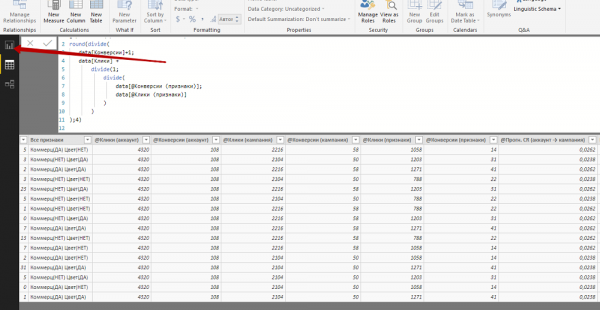
6. Добавим в таблицу нужные нам столбцы: «Ключевое слово», «Клики», «Конверсии», «_CR» и «@Прогн. CR (признаки → ключевое слово)».
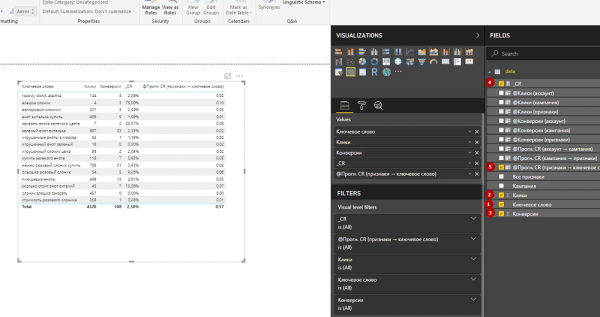
7. Чтобы прогноз CR отображался в процентном формате, выделим название столбца, откроем вкладку Modeling и нажмем кнопку %.
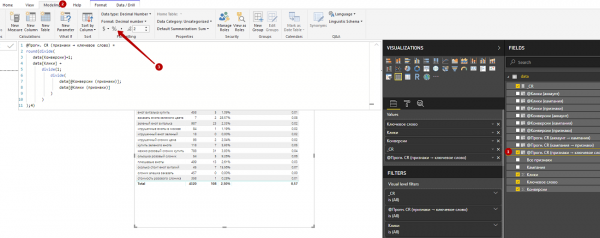
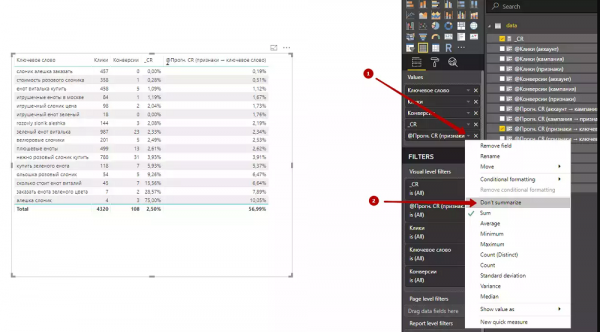
8. Теперь уберем сумму значений из столбца «@Прогн. CR (признаки → ключевое слово)».
Вместо заключения
Мы получили таблицу с прогнозом CR для каждого ключевого слова в семантическом ядре. В том числе для фраз, у которых фактический CR нерепрезентативен из-за недостатка статистики или вообще отсутствует, поскольку нет ни одной конверсии. Теперь мы можем оптимизировать наши кампании: сократить расходы на запросы, у которых прогнозируется низкий CR, и увеличить ставки для фраз, сулящих хорошую конверсию.
Источник: seonews.ru


